Split up your logs with $pl1tR
Drop what you don't need and save costs. What's not to like?!

Introduction
If you found this article you probably already know: ingesting logs can be expensive. That's why more and more people resort to looking into combining other Azure services like Azure Data Explorer and Blob storage alongside their Microsoft Sentinel and Log Analytics workspaces.
But sometimes you just need your logs on high performance storage. Maybe this is because you're actively triggering security incidents from Sentinel, or maybe because you simple need the query performance for hunting or other data analytics cases. Then, it's great if you're able to filter out logs in transit of which you already know you won't be needing them.
When using external log collectors like Logstash, we already had a couple of options available to us. Either filter on the source, within Logstash or transform within the Data Collection Rule responsible for storing the logs into the workspace.
But what about Azure resource logs like the ones coming from your Storage Account, Key Vault or AKS cluster? Those are stored natively via Microsoft's back-end, and there's nothing in between. Or is there?
Well, Data Collection Rules can be attached to Log Analytics Workspaces as well and can be used to transform data on ingest. Even for default Microsoft tables like those resources use I mentioned earlier!
This article will guide you through the basics of setting up such a Data Collection Rule type. But it will also introduce you to a tool I've created, named log-splitr. This can generate such DCR's automatically for you! This way you can integrate this process into your Infrastructure-as-Code pipelines as well!
 PPlease visit my Github repository to get started with
PPlease visit my Github repository to get started with log-split.ps1!
How it works
With a workspace-level Data Collection Rule you cannot only transform the logs before they enter the destination table, it also allows for log streams to be split into more than one table.
This allows us to use one transformation to split parse and filter our logs coming in, and send the original untouched logs into a secondary table with a Basic tier for example!
I've written an article earlier about the different table tiers available like Analytics, Basic and Archive. Please check it out if you're interested.
Microsoft announced workspace-level Data Collection Rules and transformations earlier in 2023 and Matthew Lowe blogged about it in June.
The easiest way to get started with table-level transforms is by going into the table overview of your log analytics workspace. Click the three dots and select "Create transformation".

This will open up a wizard asking you to the create the Data Collection Rule and provide a transformation query (more on this later). Next, if you repeat this step, you'll notice that "Create transformation" is now labeled "Edit transformation".
Keep in mind that not all tables are currently supported to apply transformations on! If "Create transformation" is greyed out, the table is probably not supported. 🤨 Please find the complete list in this Microsoft doc here.
Unfortunately this approach will not provide an option to use multiple destinations. We need to dig into the code to archieve this. But it's good to understand how the DCR is constructed because we want to implement this into my Infrastructure-as-Code deployment pipelines.
Split into multiple streams
When we look at the DCR that was created earlier, we’ll notice a couple of things:
- This Data Collection Rule uses a
kindproperty ofWorkspaceTransformswhich is different (and undocumented in the ARM reference documentation!) than we're used to. - Within the
dataFlowsproperty we'll find astreampointing to a tablename with aMicrosoft-Table-prefix. (Where custom log tables always use theCustom-prefix) - The workspace now has a
DefaultDataCollectionRuleResourceIdproperty assigned with a value of said DCR's resource ID.
When looking at Microsoft's documentation on the subject, you might find defining multiple streams for log splitting a bit confusing. Here's a simple example showing logs coming in from a Storage Account (send to the StorageFileLogs table) and split into the standard table with some filtering (only keep the 'delete' actions) but also send to a custom table StorageFileLogs_CL in its original form:
"destinations": [
"[parameters('workspaceName')]"
],
"streams": [
"Microsoft-Table-StorageFileLogs"
],
"transformKql": "source\n| where OperationName == 'DeleteFile' or \n OperationName == 'Flush' or \n Category == 'StorageDelete'\n"
},
{
"destinations": [
"[parameters('workspaceName')]"
],
"outputStream": "Custom-StorageFileLogs_CL",
"streams": [
"Microsoft-Table-StorageFileLogs"
],
"transformKql": "source\n"
}As you can see it's very important to distinguish the two. The streams are both the same and the destination is as well. But sending the original logs to the custom table requires an additional property outputStreams. You also have to be careful with table definitions and apply the correct prefixes as mentioned earlier.

Impact on cost
In the example above we only kept delete actions for our storage account diagnostic logs because we want to trigger a security incident for those action in Sentinel.
This means that we're dropping most of the logs coming in. (less than 0,1 %) That is a huge cost saver! BUT! but! (there's always a but….) Microsoft will charge you for logs processed and not stored inside the table when certain parameters are met:
- Transformation drops more than 50% of the total volume of logs
- The workspace does not have the Sentinel solution running on top. In other words; Sentinel workspaces are not affected by this.
When data processing charges are applied, I think this is still reasonable since all of your data did still touch the ingestion pipelines of Microsoft and they had to process your total volume of data in one way or another.
For more details on these charges, and a couple of examples, please check out Microsoft's documentation on this subject.
Create a DCR from scratch
In my research I also came across a nice blogpost from Alistair Ross. His approach is to make use of Azure Workbooks which can generate the ARM template for the DCR fully automatic!
Although I needed a more flexible approach, one I can use from Github Actions or Azure DevOps pipelines and integrate into my Infrastructure-as-Code deployments, his workbook gave me some very valuable insights in how this type of Data Collection Rule needs to be constructed! 👌🏻
I'm currently working for a large global enterprise and their SOC is also responsible for determing what logs go where. But there's obvious communication back and forth about the costs associated with them. But since they also have full control over the analytic using these logs, this makes sense.
Their SOC team is very capable in a lot of things but creating ARM templates for Data Collection Rules is not their cup of tea. So, I was asked to come up with a solution where the security division has easy control over log filtering for Azure resources on a per table basis. They want to have the option to either filter the logs coming into the table and optionally opt for a custom table to be created where the original logs will be kept untouched.
This is where
$pl1tRcomes in!
Yes, I'm a kid of the 80’s and 90’s! 😎 This means I grew up interacting with BBSes, demo's and ASCII- and ANSi-art made by the demo-scene! I like to implement some ASCII-art into my source code as well as a nod to this time period. If you want to learn more about this, please take a look at the “holiday special” I published earlier about these subjects.
Since "Splitter" is saving you money, I just HAD to place a dollar sign instead of that 'S' at the beginning, right?
log-splitr.ps1
With $pl1tR you can provide a folder with YAML files containing table definitions, each with their transformation queries and a few other properties. These files will be imported and used to construct a Data Collection Rule.
Here's an example of a table called StorageFileLogs a default table used by Azure Storage Accounts when diagnostics logs are enabled.
tableName: StorageFileLogs
analyticsRetentionInDays: 180
analyticsTransform: |
source
| where OperationName == 'DeleteFile' or
OperationName == 'Flush' or
Category == 'StorageDelete'
basicEnabled: true
basicRetentionInDays: 8
basicTransform: |
sourceIn this particular example you’ll see that we only keep deletion events of files and drop all other logs by making sure the analyticsTransform property contains the right KQL query.
Next, we have the property basicEnabled set to true which means we'll make sure that there is a custom log table (in Basic tier) with the same schema and name (but with a _CL suffix obviously). All logs in an unaltered state will be streamed to this table because the transformation query (basicTransform) is left default.
The YAML defined here resulted in exactly the DCR code showed in an earlier paragraph above!
This way you can easily create a folder structure for all of your workspaces and within each workspace folder place the respective table transformations as YAML files.
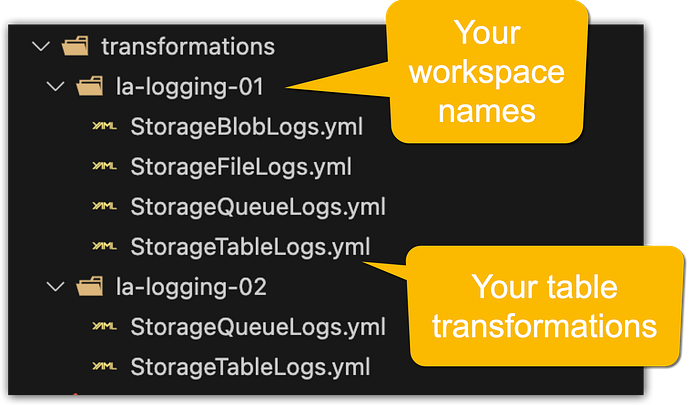
basicEnabled: true
When a Basic custom log table needs to be created, this results in an additional resource deployment within the same template. And because now the DCR deployment depends on that table as well, a dependsOn property is added for every custom table that needs to be created as well!
To create a "replica" custom logs table of the original, log-splitr retrieves the schema of the orginal table for you and uses this as input for the custom table deployment.
In my Github repository you'll find a couple of sample YAML files but also a sample ARM template for a DCR that was the result of an earlier run. Hopefully this helps you understand all the legwork
log-splitris taking care of for you.
Parameters
There are a couple of parameters you need to use and one optional parameter you can use.
SubscriptionIdThe subscription ID of the Azure subscription you want to deploy to and where your workspace resides.WorkspaceNameName of the Log Analytics / Sentinel workspace you want to create the DCR for.PathToYamlFileLocation of YAML files with table definitions for this specific workspace.ResourceGroupNameResource group you want to deploy the DCR to.SaveTemplateAdd this switch if you want to store the template to file. This helps with debugging but you also might want to use this script one-time only.
Example
./log-splitr.ps1 `
-WorkspaceName "la-workspace-01" `
-SubscriptionId "<subscriptionid>" `
-PathToYamlFiles "./transformations/la-logging-01/" `
-ResourceGroupName "rg-logging-01" `
-saveTemplate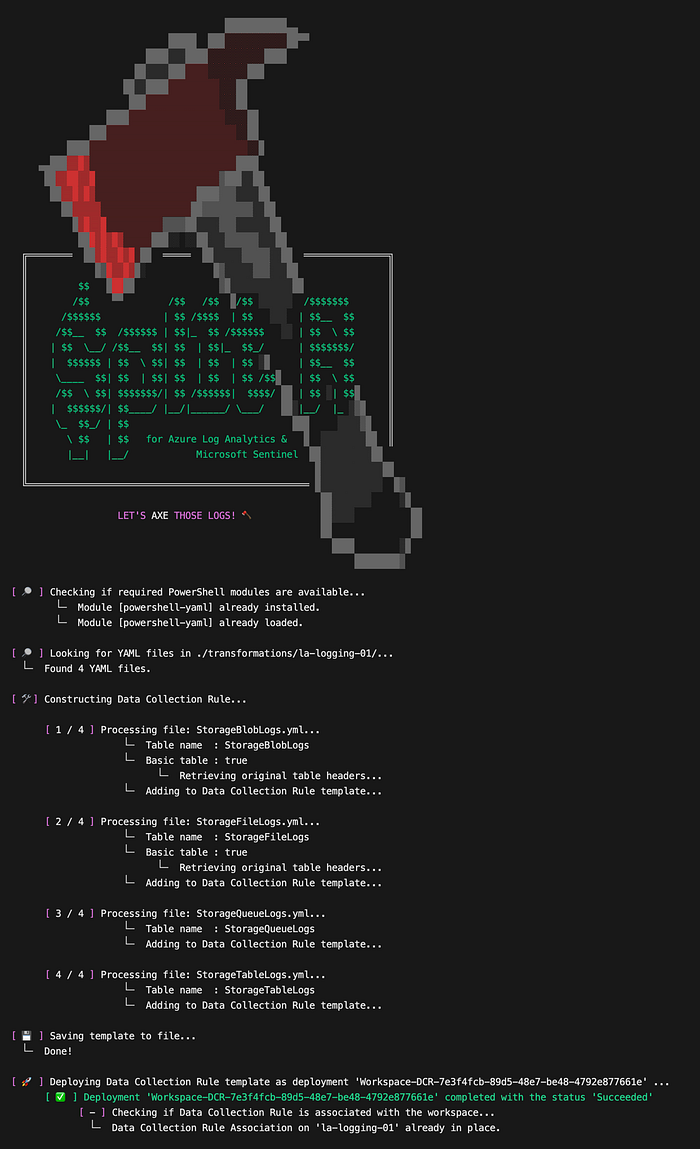
Conclusion
I hope everything was clearly explained and it sparked enough interest to check out log-splitr yourself.
If you have any follow-up questions don’t hesitate to reach out to me. Also follow me here on Medium or keep an eye on my Twitter and LinkedIn feeds to get notified about new articles here on Medium.
I still wouldn’t call myself an expert on PowerShell. So if you have feedback on any of my approaches, please let me know! Also never hesitate to fork my repository and submit a pull request. They always make me smile because I learn from them and it will help out others using these tools. 👌🏻
I hope you like this tool and it will make your environment safer as well!
— Koos